RAG(検索拡張生成)
LLMの知識はトレーニングされたデータに限定されています。 LLMにドメイン固有の知識や独自データを認識させたい場合、以下の方法があります:
- このセクションで説明するRAGを使用する
- 自分のデータでLLMをファインチューニングする
- RAGとファインチューニングの両方を組み合わせる
RAGとは?
簡単に言えば、RAGはLLMに送信する前に、プロンプト�にデータから関連情報を見つけて挿入する方法です。 これによりLLMは(うまくいけば)関連情報を取得し、その情報を使用して回答できるようになり、 幻覚の可能性を減らすことができます。
関連情報はさまざまな情報検索方法で見つけることができます。 最も一般的なものは:
- 全文(キーワード)検索。この方法はTF-IDFやBM25などの技術を使用して、 クエリ(ユーザーが尋ねていること)のキーワードをドキュメントデータベースと照合して検索します。 各ドキュメント内のキーワードの頻度と関連性に基づいて結果をランク付けします。
- ベクトル検索(「意味検索」とも呼ばれる)。 テキストドキュメントは埋め込みモデルを使用して数値のベクトルに変換されます。 クエリベクトルとドキュメントベクトル間のコサイン類似度や その他の類似度/距離測定に基づいてドキュメントを検索しランク付けし、 より深い意味を捉えます。
- ハイブリッド。複数の検索方法(全文+ベクトルなど)を組み合わせると、通常は検索の効果が向上します。
現在、このページは主にベクトル検索に焦点を当てています。
全文検索とハイブリッド検索は現在、Azure AI Search統合でのみサポートされています。
詳細はAzureAiSearchContentRetrieverを参照してください。
近い将来、全文検索とハイブリッド検索を含むRAGツールボックスを拡張する予定です。
RAGの段階
RAGプロセスは、インデックス作成と検索という2つの明確な段階に分かれています。 LangChain4jは両方の段階のためのツールを提供しています。
インデックス作成
インデックス作成段階では、検索段階で効率的な検索を可能にするようにドキュメントが前処理されます。
このプロセスは使用される情報検索方法によって異なります。 ベクトル検索の場合、通常はドキュメントのクリーニング、追加データとメタデータによる強化、 小さなセグメント(チャンキングとも呼ばれる)への分割、これらのセグメントの埋め込み、 最後に埋め込みストア(ベクトルデータベースとも呼ばれる)への保存が含まれます。
インデックス作成段階は通常オフラインで行われ、エンドユーザーがその完了を待つ必要はありません。 これは例えば、週末に社内ドキュメントを週に一度再インデックス化するcronジョブを通じて実現できます。 インデックス作成を担当するコードは、インデックス作成タスクのみを処理する別のアプリケーションにすることもできます。
ただし、一部のシナリオでは、エンドユーザーがLLMがアクセスできるようにカスタムドキュメントをアップロードしたい場合があります。 この場合、インデックス作成はオンラインで行われ、メインアプリケーションの一部である必要があります。
以下はインデックス作成段階の簡略化された図です:
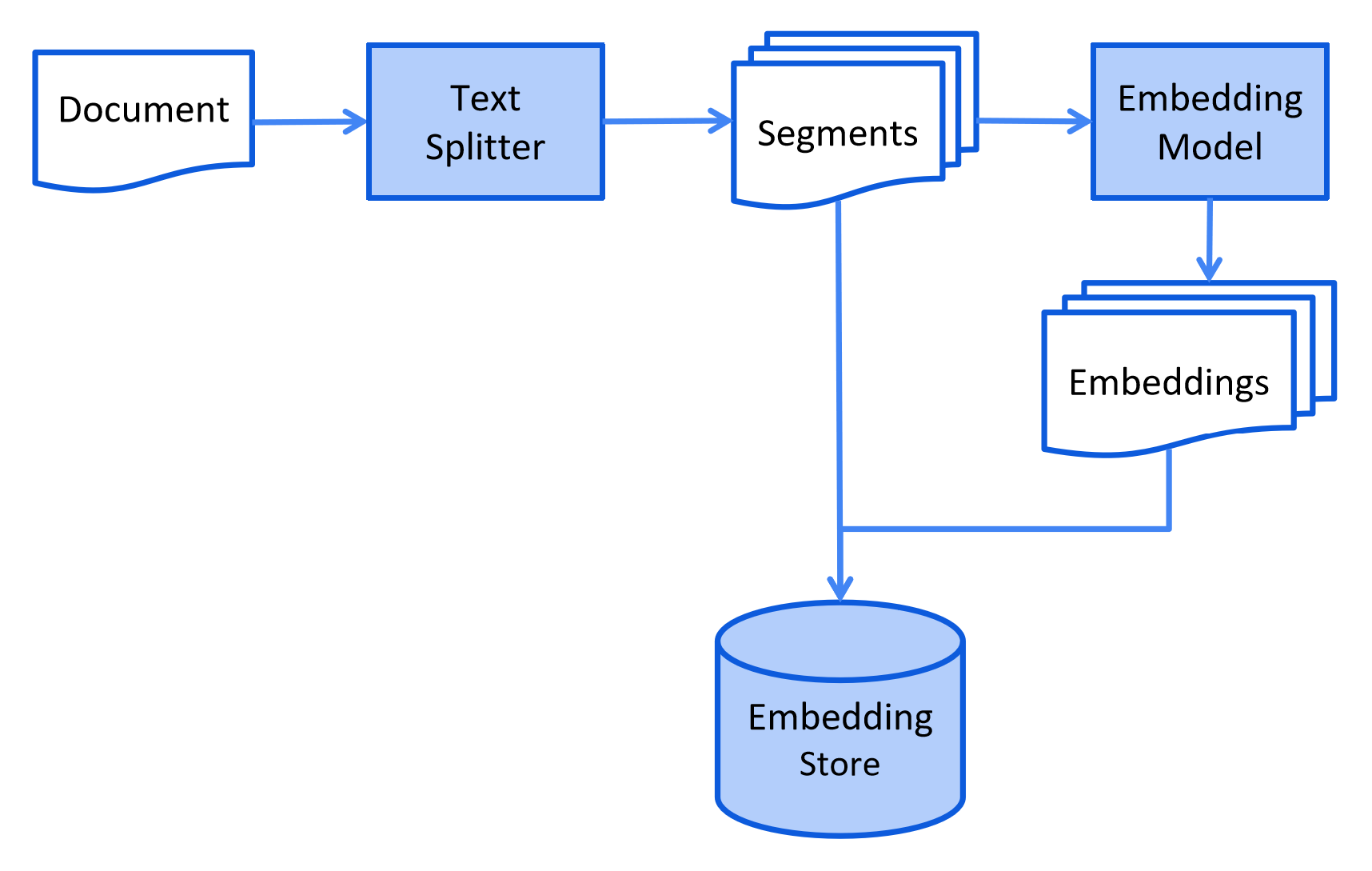
検索
検索段階は通常、ユーザーがインデックス付きドキュメントを使用して回答すべき質問を送信したときに、オンラインで行われます。
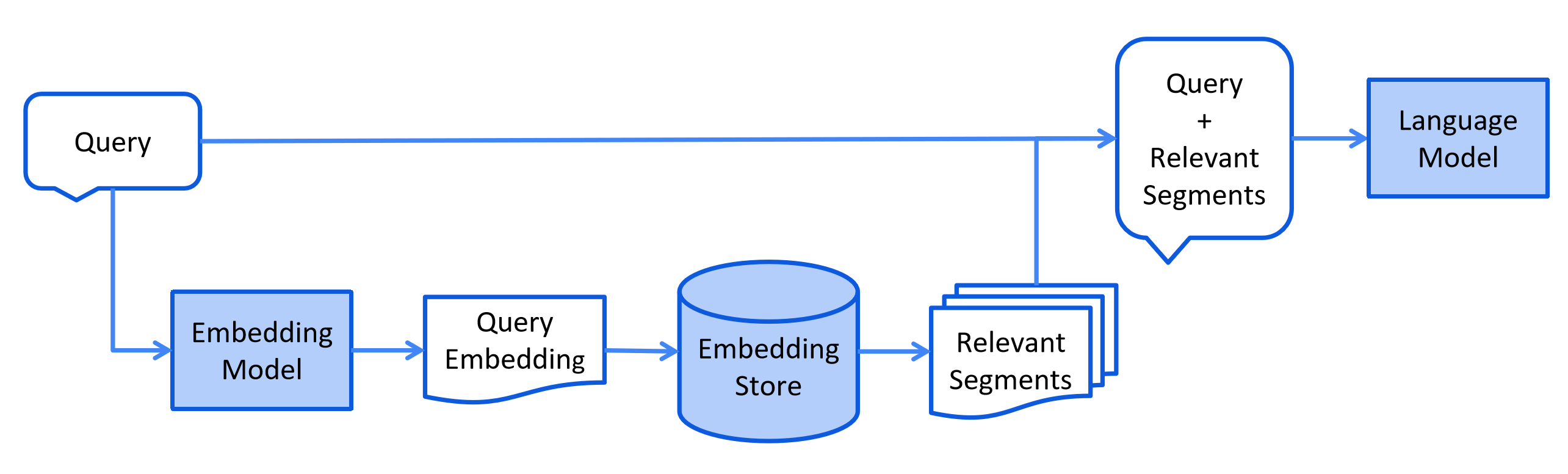
このプロセスは使用される情報検索方法によって異なります。 ベクトル検索の場合、通常はユーザーのクエリ(質問)を埋め込み、 埋め込みストアで類似性検索を実行します。 関連するセグメント(元のドキュメントの一部)がプロンプトに挿入され、LLMに送信されます。
以下は検索段階の簡略化された図です:
LangChain4jのRAGフレーバー
LangChain4jは3つのRAGフレーバーを提供しています:
- Easy RAG:RAGを始める最も簡単な方法
- Naive RAG:ベクトル検索を使用したRAGの基本的な実装
- Advanced RAG:クエリ変換、複数ソースからの検索、再ランキングなどの追加ステップを可能にするモジュラーRAGフレームワーク
Easy RAG
LangChain4jには、RAGを始めるのをできるだけ簡単にする「Easy RAG」機能があります。 埋め込みについて学んだり、ベクトルストアを選んだり、適切な埋め込みモデルを見つけたり、 ドキュメントの解析や分割方法を理解したりする必要はありません。 ドキュメントを指定するだけで、LangChain4jが魔法をかけます。
カスタマイズ可能なRAGが必要な場合は、次のセクションにスキップしてください。
Quarkusを使用している場合は、さらに簡単にEasy RAGを行う方法があります。 Quarkusのドキュメントをお読みください。
もちろん、このような「Easy RAG」の品質は、調整されたRAGセットアップよりも低くなります。 しかし、これはRAGについて学び始めたり、概念実証を作成したりする最も簡単な方法です。 後で、Easy RAGからより高度なRAGへスムーズに移行し、 より多くの側面を調整およびカスタマイズすることができます。
langchain4j-easy-rag依存関係をインポートします:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta4</version>
</dependency>
- ドキュメントを読み込みましょう:
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
これにより、指定されたディレクトリからすべてのファイルが読み込まれます。
内部で何が起きているのか?
幅広いドキュメントタイプをサポートするApache Tikaライブラリが、
ドキュメントタイプを検出して解析するために使用されます。
どのDocumentParserを使用するかを明示的に指定しなかったため、
FileSystemDocumentLoaderはSPIを通じてlangchain4j-easy-rag依存関係によって提供される
ApacheTikaDocumentParserを読�み込みます。
ドキュメントの読み込みをカスタマイズする方法は?
すべてのサブディレクトリからドキュメントを読み込みたい場合は、loadDocumentsRecursivelyメソッドを使用できます:
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j/documentation");
さらに、globまたは正規表現を使用してドキュメントをフィルタリングできます:
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.pdf");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation", pathMatcher);
loadDocumentsRecursivelyメソッドを使用する場合、globで二重アスタリスク(単一ではなく)を使用することをお勧めします:glob:**.pdf。
- 次に、ドキュメントを前処理し、特殊な埋め込みストア(ベクトルデータベースとも呼ばれる)に保存する必要があります。 これは、ユーザーが質問したときに関連情報をすばやく見つけるために必要です。 15以上のサポートされている埋め込みストアのいずれかを使用できますが、 簡単にするためにインメモリのものを使用します:
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
内部で何が起きているのか?
-
EmbeddingStoreIngestorはSPIを通じてlangchain4j-easy-rag依存関係からDocumentSplitterを読み込みます。 各Documentは、それぞれが300トークン以下で30トークンのオーバーラップを持つ小さな部分(TextSegment)に分割されます。 -
EmbeddingStoreIngestorはSPIを通じてlangchain4j-easy-rag依存関係からEmbeddingModelを読み込みます。 各TextSegmentはEmbeddingModelを使用してEmbeddingに変換されます。
Easy RAGのデフォルト埋め込みモデルとしてbge-small-en-v1.5を選択しました。 MTEBリーダーボードで印象的なスコアを達成し、 その量子化バージョンはわずか24メガバイトのスペースしか占めません。 したがって、ONNXランタイムを使用して、 簡単にメモリにロードし、同じプロセスで実行できます。
そうです、テキストを埋め込みに変換することは、外部サービスなしで、 同じJVMプロセス内で完全にオフラインで行うことができます。 LangChain4jは5つの人気のある埋め込みモデルを すぐに使える形で提供しています。
- すべての
TextSegment-EmbeddingペアがEmbeddingStoreに保存されます。
- 最後のステップは、LLMへのAPIとして機能するAIサービスを作成することです:
interface Assistant {
String chat(String userMessage);
}
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(ChatModel) // 任意のLLM
.contentRetriever(EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(EmbeddingModel) // 任意の埋め込みモデル
.maxResults(3)
.build())
.build();
String answer = assistant.chat("LangChain4jのRAGについて教えてください");
内部で何が起きているのか?
-
assistant.chat("LangChain4jのRAGについて教えてください")が呼び出されると、EmbeddingStoreContentRetrieverはEmbeddingModelを使用してクエリを埋め込みます。 -
EmbeddingStoreContentRetriever��は埋め込みストアで類似性検索を実行し、 クエリに最も関連する3つのTextSegmentを取得します。 -
これらの
TextSegmentはプロンプトに挿入され、LLMに送信されます。 -
LLMは提供された情報を使用して回答を生成します。
Easy RAGの制限は?
Easy RAGは、RAGを始めるための最も簡単な方法ですが、いくつかの制限があります:
- 英語のみをサポートしています。
- 埋め込みモデルはJVMプロセス内で実行されるため、大きなドキュメントコレクションには適していません。
- 埋め込みストアはインメモリであるため、アプリケーションの再起動時にすべてのデータが失われます。
- ドキュメントの分割方法をカスタマイズすることはできません。
- 検索結果の数をカスタマイズすることはできません。
- 検索結果のフィルタリングはできません。
- 検索結果の再ランキングはできません。
- 検索結果の後処理はできません。
- 複数のソースからの検索はできません。
- クエリの変換はできません。
- 検索結果の最小類似度スコアを設定することはできません。
- 検索結果の最大数を動的に設定することはできません。
- 検索結果のフィルタを動的に設定することはできません。
- 検索結果の最小類似度スコアを動的に設定することはできません。
- 検索結果の再ランキングを動的に設定することはできません。
- 検索結果の後処理を動的に設定することはできません��。
- 複数のソースからの検索を動的に設定することはできません。
- クエリの変換を動的に設定することはできません。
- 検索結果の最小類似度スコアを動的に設定することはできません。
RAG APIs
LangChain4jは、RAGの実装に使用できる一連のAPIを提供しています。 これらのAPIは、RAGの各段階(インデックス作成と検索)に対応しています。
Document
Documentクラスは、テキストとメタデータを含むドキュメントを表します。
メタデータは、ドキュメントに関する追加情報を提供するキーと値のペアのマップです。
例えば、ファイル名、作成日、著者、タイトルなどです。
便利なメソッド
Document.text()はDocumentのテキストを返しますDocument.metadata()はDocumentのMetadataを返しますDocument.from(String, Metadata)はテキストとMetadataからDocumentを作成しますDocument.from(String)はテキストから空のMetadataを持つDocumentを作成します
Document Loader
DocumentLoaderインターフェースは、さまざまなソースからドキュメントを読み込むための抽象化を提供します。
LangChain4jには、いくつかの組み込み実装があります:
FileSystemDocumentLoaderUrlDocumentLoaderS3DocumentLoader
便利なメソッド
DocumentLoader.loadDocument()は単一のDocumentを読み込みますDocumentLoader.loadDocuments()は複数のDocumentを読み込みます
Document Parser
DocumentParserインターフェースは、さまざまな形式のドキュメントを解析するための抽象化を提供します。
LangChain4jには、いくつかの組み込み実装があります:
TextDocumentParserApacheTikaDocumentParserMsOfficeDocumentParserPdfBoxDocumentParser
便利なメソッド
DocumentParser.parse(InputStream, Metadata)は入力ストリームとメタデータからDocumentを解析します
Document Transformer
DocumentTransformerはDocumentを変換します。
これは、ドキュメントをクリーニングしたり、追加情報で強化したりするのに役立ちます。
一般的なソリューションはないため、独自のDocumentTransformerを実装することをお勧めします。
これは、特定のデータに合わせてカスタマイズする必要があります。
Text Segment
TextSegmentクラスは、テキストとメタデータを含むテキストセグメントを表します。
これはDocumentに似ていますが、通常はより小さなテキスト単位を表します。
TextSegmentは通常、Documentを分割することで作成されます。
なぜドキュメントを分割するのですか?
ドキュメントを分割する主な理由は2つあります:
- LLMのコンテキストウィンドウ(プロンプトに入れることができるトークンの最大数)は限られています。 ドキュメント全体がコンテキストウィンドウに収まらない場合、分割する必要があります。
- ベクトル検索は、ドキュメント全体よりも小さなセグメントで機能します。 ドキュメントを小さなセグメントに分割することで、ベクトル検索の品質が向上します。
ただし、ドキュメントを分割すると、コンテキストが失われる可能性があります。 例えば、セグメントが「彼は賢い」である場合、「彼」が誰を指している��のかわかりません。
一般的な戦略は、オーバーラップを持つセグメントにドキュメントを分割することですが、これは問題を完全に解決するものではありません。 「文章ウィンドウ検索」、「自動マージ検索」、「親ドキュメント検索」などのいくつかの高度な技術がここで役立ちます。 ここでは詳細に触れませんが、基本的にこれらの方法は、検索されたセグメントの前後に追加の情報を取得し、 LLMに検索されたセグメントの前後の追加コンテキストを提供するのに役立ちます。
- 長所:
- ベクトル検索の品質が向上します。
- トークン消費が減少します。
- 短所:一部のコンテキストが失われる可能性があります。
便利なメソッド
TextSegment.text()はTextSegmentのテキストを返しますTextSegment.metadata()はTextSegmentのMetadataを返しますTextSegment.from(String, Metadata)はテキストとMetadataからTextSegmentを作成しますTextSegment.from(String)はテキストから空のMetadataを持つTextSegmentを作成します
Document Splitter
LangChain4jには、いくつかの組み込み実装を持つDocumentSplitterインターフェースがあります:
DocumentByParagraphSplitterDocumentByLineSplitterDocumentBySentenceSplitterDocumentByWordSplitterDocumentByCharacterSplitterDocumentByRegexSplitter- 再帰的:
DocumentSplitters.recursive(...)
これらはすべて次のように機能します:
DocumentSplitterをインスタンス化し、希望するTextSegmentのサイズと、 オプションで文字またはトークンでのオーバーラップを指定します。DocumentSplitterのsplit(Document)またはsplitAll(List<Document>)メソッドを呼び出します。DocumentSplitterは与えられたDocumentをより小さな単位に分割します。 その性質はスプリッターによって異なります。例えば、DocumentByParagraphSplitterは ドキュメントを段落(2つ以上の連続した改行文字で定義)に分割し、DocumentBySentenceSplitterはOpenNLPライブラリの文検出器を使用して ドキュメントを文に分割するなどです。DocumentSplitterはこれらの小さな単位(段落、文、単語など)をTextSegmentに結合し、 ステップ1で設定された制限を超えることなく、できるだけ多くの単位を1つのTextSegmentに含めようとします。 一部の単位がまだ大きすぎてTextSegmentに収まらない場合、サブスプリッターを呼び出します。 これは、収まらない単位をより細かい単位に分割できる別のDocumentSplitterです。 すべてのMetadataエントリはDocumentから各TextSegmentにコピーされます。 各テキストセグメントには一意のメタデータエントリ「index」が追加されます。 最初��のTextSegmentにはindex=0、2番目にはindex=1などが含まれます。
Text Segment Transformer
TextSegmentTransformerはDocumentTransformer(上記で説明)と似ていますが、TextSegmentを変換します。
DocumentTransformerと同様に、万能なソリューションはないため、
独自のデータに合わせた独自のTextSegmentTransformerを実装することをお勧めします。
検索を改善するためによく機能する1つの技術は、各TextSegmentにDocumentのタイトルや短い要約を含めることです。
Embedding
Embeddingクラスは、埋め込まれたコンテンツ(通常はTextSegmentなどのテキスト)の
「意味的な意味」を表す数値ベクトルをカプセル化します。
ベクトル埋め込みについての詳細はこちらをご覧ください:
- https://www.elastic.co/what-is/vector-embedding
- https://www.pinecone.io/learn/vector-embeddings/
- https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings
便利なメソッド
Embedding.dimension()は埋め込みベクトルの次元(長さ)を返しますCosineSimilarity.between(Embedding, Embedding)は2つのEmbedding間のコサイン類似度を計算しますEmbedding.normalize()は埋め込みベクトルを正規化します(その場で)
Embedding Model
EmbeddingModelインターフェースは、テキストをEmbeddingに変換する特殊なタイプのモデルを表します。
現在サポートされている埋め込みモデルはこちらで確認できます。
便利なメソッド
EmbeddingModel.embed(String)は与えられたテキストを埋め込みますEmbeddingModel.embed(TextSegment)は与えられたTextSegmentを埋め込みますEmbeddingModel.embedAll(List<TextSegment>)は与えられたすべてのTextSegmentを埋め込みますEmbeddingModel.dimension()はこのモデルによって生成されるEmbeddingの次元を返します
Embedding Store
EmbeddingStoreインターフェースは、TextSegmentとEmbeddingのペアを保存および検索するためのストレージを表します。
現在サポートされている埋め込みストアはこちらで確認できます。
便利なメソッド
EmbeddingStore.add(Embedding, TextSegment)はEmbeddingとTextSegmentのペアを追加しますEmbeddingStore.addAll(List<Embedding>, List<TextSegment>)はEmbeddingとTextSegmentのペアのリストを追加しますEmbeddingStore.findRelevant(Embedding, int)は与えられたEmbeddingに最も関連するTextSegmentを見つけますEmbeddingStore.findRelevant(Embedding, int, double)は与えられたEmbeddingに最も関連するTextSegmentを見つけ、最小スコアでフィルタリングしますEmbeddingStore.findRelevant(Embedding, int, Metadata)は与えられたEmbeddingに最も関連するTextSegmentを見つけ、メタデータでフィルタリングしますEmbeddingStore.findRelevant(Embedding, int, double, Metadata)は与えられたEmbeddingに最も関連するTextSegmentを見つけ、最小スコアとメタデータでフィルタリングします
Embedding Store Ingestor
EmbeddingStoreIngestorは、DocumentをTextSegmentに分割し、それらを埋め込み、EmbeddingStoreに保存するユーティリティクラスです。
便利なメソッド
EmbeddingStoreIngestor.ingest(List<Document>, EmbeddingStore, DocumentSplitter, EmbeddingModel)はDocumentをTextSegmentに分割し、それらを埋め込み、EmbeddingStoreに保存しますEmbeddingStoreIngestor.ingest(List<Document>, EmbeddingStore, DocumentSplitter, DocumentTransformer, EmbeddingModel)はDocumentを変換し、TextSegmentに分割し、それらを埋め込み、EmbeddingStoreに保存しますEmbeddingStoreIngestor.ingest(List<Document>, EmbeddingStore, DocumentSplitter, DocumentTransformer, TextSegmentTransformer, EmbeddingModel)はDocumentを変換し、TextSegmentに分割し、それらを変換し、埋め込み、EmbeddingStoreに保存します
EmbeddingSearchRequest
EmbeddingSearchRequestはEmbeddingStoreでの検索リクエストを表します。
以下の属性があります:
Embedding queryEmbedding:参照として使用される埋め込み。int maxResults:返す結果の最大数。これはオプションのパラメータです。デフォルト:3。double minScore:0から1(含む)の範囲の最小スコア。スコア >=minScoreの埋め込みの��みが返されます。これはオプションのパラメータです。デフォルト:0。Filter filter:検索中にMetadataに適用されるフィルター。Filterに一致するMetadataを持つTextSegmentのみが返されます。
Filter
Filterはベクトル検索を実行する際にMetadataエントリによるフィルタリングを可能にします。
現在、以下のFilterタイプ/操作がサポートされています:
IsEqualToIsNotEqualToIsGreaterThanIsGreaterThanOrEqualToIsLessThanIsLessThanOrEqualToIsInIsNotInContainsStringAndNotOr
すべての埋め込みストアがMetadataによるフィルタ��リングをサポートしているわけではありません。
こちらの「Filtering by Metadata」列を参照してください。
Metadataによるフィルタリングをサポートするストアでも、すべての可能なFilterタイプ/操作をサポートしているわけではありません。
例えば、ContainsStringは現在、Milvus、PgVector、Qdrantでのみサポートされています。
Filterについての詳細はこちらで確認できます。
EmbeddingSearchResult
EmbeddingSearchResultはEmbeddingStoreでの検索結果を表します。
EmbeddingMatchのリストが含まれています。
Embedding Match
EmbeddingMatchは、関連性スコア、ID、および元の埋め込みデータ(通常はTextSegment)と共にマッチしたEmbeddingを表します。
Embedding Store Ingestor
EmbeddingStoreIngestorは取り込みパイプラインを表し、DocumentをEmbeddingStoreに取り込む責任があります。
最も単純な構成では、EmbeddingStoreIngestorは指定されたEmbeddingModelを使用して提供されたDocumentを埋め込み、
それらをEmbeddingと共に指定されたEmbeddingStoreに格納します:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document1);
ingestor.ingest(document2, document3);
IngestionResult ingestionResult = ingestor.ingest(List.of(document4, document5, document6));
EmbeddingStoreIngestorのすべてのingest()メソッドはIngestionResultを返します。
IngestionResultには、埋め込みに使用されたトークン数を示すTokenUsageなど、有用な情報が含まれています。
オプションで、EmbeddingStoreIngestorは指定されたDocumentTransformerを使用してDocumentを変換できます。
これは、埋め込む前にDocumentをクリーニング、強化、またはフォーマットしたい場合に便利です。
オプションで、EmbeddingStoreIngestorは指定されたDocumentSplitterを使用してDocumentをTextSegmentに分割できます。
これは、Documentが大きく、類似性検索の品質を向上させ、LLMに送信されるプロンプトのサイズとコストを削減するために、
より小さなTextSegmentに分割したい場合に便利です。
オプションで、EmbeddingStoreIngestorは指定されたTextSegmentTransformerを使用してTextSegmentを変換できます。
これは、埋め込む前にTextSegmentをクリーニング、強化、またはフォーマットしたい場合に便利です。
例:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
// 後でフィル�タリングできるように、各DocumentにユーザーIDメタデータエントリを追加
.documentTransformer(document -> {
document.metadata().put("userId", "12345");
return document;
})
// 各Documentを1000トークンの TextSegmentに分割し、200トークンのオーバーラップを持たせる
.documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenCountEstimator("gpt-4o-mini")))
// 検索品質を向上させるために、各TextSegmentにDocumentの名前を追加
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata().getString("file_name") + "\n" + textSegment.text(),
textSegment.metadata()
))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ナイーブRAG
ドキュメントが取り込まれたら(前のセクションを参照)、
EmbeddingStoreContentRetrieverを作成してナイーブRAG機能を有効にできます。
AIサービスを使用する場合、ナイーブRAGは次のように構成できます:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5)
.minScore(0.75)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(model)
.contentRetriever(contentRetriever)
.build();
高度なRAG
LangChain4jでは、以下のコアコンポーネントを使用して高度なRAGを実装できます:
QueryTransformerQueryRouterContentRetrieverContentAggregatorContentInjector
以下の図は、これらのコンポーネントがどの�ように連携するかを示しています:
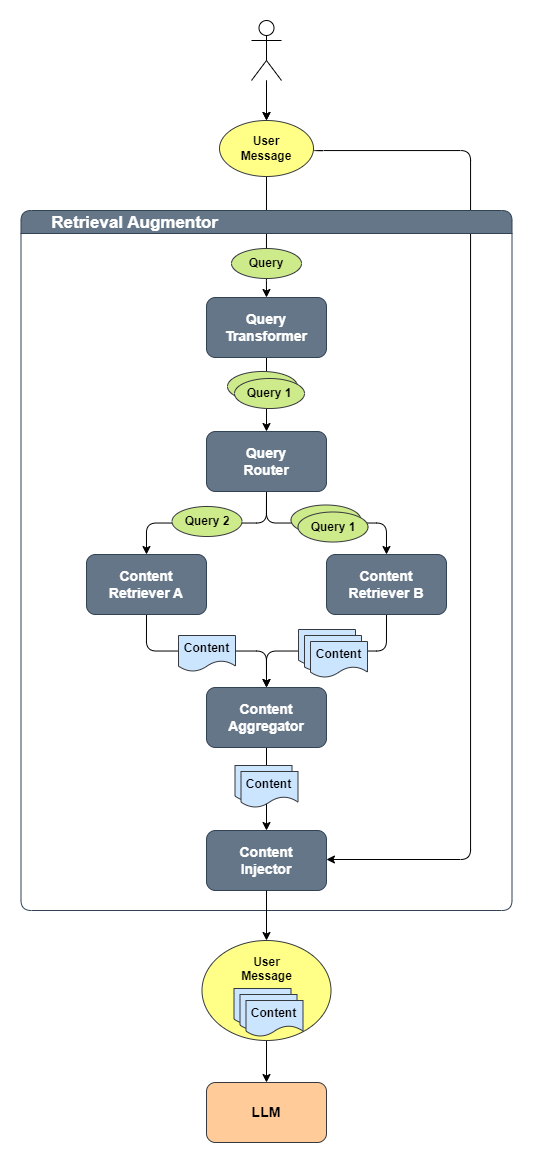
プロセスは次のとおりです:
- ユーザーが
UserMessageを生成し、それがQueryに変換されます QueryTransformerがQueryを1つまたは複数のQueryに変換します- 各
QueryはQueryRouterによって1つ以上のContentRetrieverにルーティングされます - 各
ContentRetrieverが各Queryに関連するContentを取得します ContentAggregatorがすべての取得されたContentを単一の最終ランク付きリストに結合します- この
Contentのリストが元のUserMessageに注入されます - 最後に、元のクエリと注入された関連コンテンツを含む
UserMessageがLLMに送信されます
各コンポーネントの詳細については、それぞれのJavadocを参照してください。
Retrieval Augmentor
RetrievalAugmentorはRAGパイプラインへのエントリーポイントです。
様々なソースから取得された関連ContentでChatMessageを拡張する責任があります。
RetrievalAugmentorのインスタンスは、AIサービスの作成時に指定できます:
Assistant assistant = AiServices.builder(Assistant.class)
...
.retrievalAugmentor(retrievalAugmentor)
.build();
AIサービスが呼び出されるたびに、指定されたRetrievalAugmentorが
現在のUserMessageを拡張するために呼び出されます。
RetrievalAugmentorのデフォルト実装(以下で説明)を使用するか、
カスタム実装を作成することができます。
Default Retrieval Augmentor
LangChain4jはRetrievalAugmentorインターフェースの標準実装として
DefaultRetrievalAugmentorを提供しており、これはほとんどのRAGユースケースに適しています。
これはこの記事と
この論文にインスパイアされています。
コンセプトをより良く理解するために、これらのリソースを確認することをお勧めします。
Query
QueryはRAGパイプラインにおけるユーザークエリを表します。
クエリのテキストとクエリメタデータが含まれています。
Query Metadata
Query内のMetadataには、RAGパイプラインの様々なコンポーネントで役立つ情報が含まれています。例えば:
Metadata.userMessage()- 拡張されるべき元のUserMessageMetadata.chatMemoryId()-@MemoryIdアノテーションが付いたメソッドパラメータの値。詳細はこちら。これはユーザーを識別し、取得中にアクセス制限やフィルターを適用するために使用できます。Metadata.chatMemory()- 以前のすべてのChatMessage。これはQueryが尋ねられたコンテキストを理解するのに役立ちます。
Query Transformer
QueryTransformerは与えられたQueryを1つまたは複数のQueryに変換します。
目的は、元のQueryを修正または拡張することで取得品質を向上させることです。
取得を改善するための既知のアプローチには以下があります:
- クエリ圧縮
- クエリ拡張
- クエリ書き換え
- ステップバックプロンプティング
- 仮想文書埋め込み(HyDE)
詳細はこちらで確認できます。
Default Query Transformer
DefaultQueryTransformerはDefaultRetrievalAugmentorで使用されるデフォルト実装です。
これはQueryに変更を加えず、そのまま渡します。
Compressing Query Transformer
CompressingQueryTransformerはLLMを使用して、与えられたQueryと
以前の会話を単独のQueryに圧縮します。
これは、ユーザーが以前の質問や回答の情報を参照するフォローアップ質問をする可能性がある場合に役立ちます。
例:
ユーザー:ジョン・ドーについて教えてください
AI:ジョン・ドーは...
ユーザー:彼はどこに住んでいましたか?
「彼はどこに住んでいましたか?」というクエリだけでは、 ジョン・ドーへの明示的な参照がなく、「彼」が誰を指すのか不明確なため、 必要な情報を取得できません。
CompressingQueryTransformerを使用すると、LLMは会話全体を読み取り、
「彼はどこに住んでいましたか?」を「ジョン・ドーはどこに住んでいましたか?」に変換します。
Expanding Query Transformer
ExpandingQueryTransformerはLLMを使用して、与えられたQueryを複数のQueryに拡張します。
これはLLMがQueryを様々な方法で言い換えたり再構成したりできるため、
より関連性の高いコンテンツを取得するのに役立ちます。
Content
ContentはユーザーのQueryに関連するコンテンツを表します。
現在はテキストコンテンツ(つまりTextSegment)に限定されていますが、
将来的には他のモダリティ(画像、音声、動画など)もサポートする可能性があります。
Content Retriever
ContentRetrieverは与えられたQueryを使用して、基礎となるデータソースからContentを取得します。
基礎となるデータソースは事実上何でもよいです:
- 埋め込みストア
- 全文検索エンジン
- ベクトルと全文検索のハイブリッド
- ウェブ検索エンジン
- ナレッジグラフ
- SQLデータベース
- など
ContentRetrieverによって返されるContentのリストは、関連性の高い順(最高から最低)に並べられています。
Embedding Store Content Retriever
EmbeddingStoreContentRetrieverはEmbeddingModelを使用してQueryを埋め込み、
EmbeddingStoreから関連するContentを取得します。
例:
EmbeddingStore embeddingStore = ...
EmbeddingModel embeddingModel = ...
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
// maxResultsはクエリに応じて動的に指定することもできます
.dynamicMaxResults(query -> 3)
.minScore(0.75)
// minScoreはクエリに応じて動的に指定することもできます
.dynamicMinScore(query -> 0.75)
.filter(metadataKey("userId").isEqualTo("12345"))
// filterはクエリに応じて動的に指定することもできます
.dynamicFilter(query -> {
String userId = getUserId(query.metadata().chatMemoryId());
return metadataKey("userId").isEqualTo(userId);
})
.build();
Web Search Content Retriever
WebSearchContentRetrieverはWebSearchEngineを使用してウェブから関連するContentを取得します。
サポートされているすべてのWebSearchEngine統合はこちらで確認できます。
例:
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv("GOOGLE_API_KEY"))
.csi(System.getenv("GOOGLE_SEARCH_ENGINE_ID"))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();
完全な例はこちらで確認できます。
SQL Database Content Retriever
SqlDatabaseContentRetrieverはlangchain4j-experimental-sqlモジュールにある
ContentRetrieverの実験的な実装です。
これはDataSourceとLLMを使用して、与えられた自然言語のQueryに対して
SQLクエリを生成して実行します。
詳細についてはSqlDatabaseContentRetrieverのjavadocを参照してください。
Azure AI Search Content Retriever
AzureAiSearchContentRetrieverはAzure AI Searchとの統合です。
全文検索、ベクトル検索、ハイブリッド検索、およびリランキングをサポートしています。
langchain4j-azure-ai-searchモジュールにあります。
詳細についてはAzureAiSearchContentRetrieverのJavadocを参照してください。
Neo4j Content Retriever
Neo4jContentRetrieverはNeo4jグラフデータベースとの統合です。
自然言語クエリをNeo4j Cypherクエリに変換し、
これらのクエリをNeo4jで実行することで関連情報を取得します。
langchain4j-community-neo4j-retrieverモジュールにあります。
Query Router
QueryRouterはQueryを適切なContentRetrieverにルーティングする責任があります。
Default Query Router
DefaultQueryRouterはDefaultRetrievalAugmentorで使用されるデフォルト実装です。
各Queryをすべての設定されたContentRetrieverにルーティングします。
Language Model Query Router
LanguageModelQueryRouterはLLMを使用して、与えられたQueryをどこにルーティングするかを決定します。
Content Aggregator
ContentAggregatorは以下からの複数のランク付けされたContentリストを集約する責任があります:
- 複数の
Query - 複数の
ContentRetriever - 両方
Default Content Aggregator
DefaultContentAggregatorはContentAggregatorのデフォルト実装で、
2段階の相互ランク融合(RRF)を実行します。
詳細についてはDefaultContentAggregatorのJavadocを参照してください。
Re-Ranking Content Aggregator
ReRankingContentAggregatorはCohereなどのScoringModelを使用してリランキングを実行します。
サポートされているスコアリング(リランキング)モデルの完全なリストは
こちらで確認できます。
詳細についてはReRankingContentAggregatorのJavadocを参照してください。
Content Injector
ContentInjectorはContentAggregatorによって返されたContentをUserMessageに注入する責任があります。
Default Content Injector
DefaultContentInjectorはContentInjectorのデフォルト実装で、
Contentを「Answer using the following information:」というプレフィックスと共に
UserMessageの末尾に単純に追加します。
ContentがUserMessageにどのように注入されるかを3つの方法でカスタマイズできます:
- デフォルトの
PromptTemplateをオーバーライドする:
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("{{userMessage}}\n{{contents}}"))
.build())
.build();
PromptTemplateには{{userMessage}}と{{contents}}変数が含まれている必要があることに注意してください。
DefaultContentInjectorを拡張してformatメソッドの1つをオーバーライドする- カスタム
ContentInjectorを実装する
DefaultContentInjectorは取得されたContent.textSegment()からMetadataエントリの注入もサポートしています:
DefaultContentInjector.builder()
.metadataKeysToInclude(List.of("source"))
.build()
この場合、TextSegment.text()には「content: 」プレフィックスが付加され、
Metadataの各値にはキーがプレフィックスとして付加されます。
最終的なUserMessageは次のようになります:
予約をキャンセルするにはどうすればよいですか?
以下の情報を使用して回答してください:
content: 予約をキャンセルするには、...に進みます
source: ./cancellation_procedure.html
content: キャンセルは...の場合に許可されます
source: ./cancellation_policy.html
並列化
単一のQueryと単一のContentRetrieverしかない��場合、
DefaultRetrievalAugmentorはクエリルーティングとコンテンツ取得を同じスレッドで実行します。
それ以外の場合は、処理を並列化するためにExecutorが使用されます。
デフォルトでは、修正された(keepAliveTimeが60秒ではなく1秒の)Executors.newCachedThreadPool()
が使用されますが、DefaultRetrievalAugmentorを作成するときにカスタムExecutorインスタンスを提供できます:
DefaultRetrievalAugmentor.builder()
...
.executor(executor)
.build;
ソースへのアクセス
AIサービスを使用する際に、
ソース(メッセージの拡張に使用された取得されたContent)にアクセスしたい場合、
戻り値の型をResultクラスでラップすることで簡単に行えます:
interface Assistant {
Result<String> chat(String userMessage);
}
Result<String> result = assistant.chat("LangChain4jで簡単なRAGを行うには?");
String answer = result.content();
List<Content> sources = result.sources();
ストリーミング時には、onRetrieved()メソッドを使用してConsumer<List<Content>>を指定できます:
interface Assistant {
TokenStream chat(String userMessage);
}
assistant.chat("LangChain4jで簡単なRAGを行うには?")
.onRetrieved((List<Content> sources) -> ...)
.onPartialResponse(...)
.onCompleteResponse(...)
.onError(...)
.start();